The short version: the code didn’t break because AI wrote bad code
It broke because two people were steering two different AI assistants against the same repo with slightly different mental models, different prompts, and different assumptions about what was already true. The failures weren’t dramatic. They were small, boring, expensive mismatches. Wrong file touched. Right file, wrong pattern. Correct feature, stale interface. Tests passed locally and failed once another branch landed. We spent more time reconciling intent than fixing syntax.
Hot Glue got better once we stopped treating the assistants like interchangeable pair programmers and started treating them like fast, inconsistent junior contributors with no shared memory. That changed how we split work, how we wrote prompts, and how we reviewed diffs.
This is what actually broke, who had to fix it, and what we changed after getting burned a few times.
The setup we thought would work
There were two of us building inside MakerWS, both moving fast, both using AI heavily. One of us was driving larger backend and data model changes. The other was shaping UI flows, edge cases, and cleanup work. We weren’t using the same assistant all the time, and that mattered more than I expected. Even when both assistants could produce valid code, they pushed toward different structures.
One assistant tended to preserve existing patterns and make smaller edits. The other liked broader refactors, renamed things more aggressively, and often “improved” code that wasn’t part of the task. In isolation, both behaviors were useful. In a shared codebase, they collided.
The repo itself wasn’t huge, but it had enough moving parts for coordination mistakes to hurt:
- a web app with a server-rendered frontend and client-side interactions
- API routes and background job logic
- a database schema that changed quickly in the early phases
- shared utility files used in more places than either assistant usually realized
Our initial workflow was simple. Too simple. We each opened the repo, pulled latest, gave our assistant a task, reviewed the output, ran local checks, and committed. That sounds fine until both people are modifying overlapping assumptions without noticing.
We didn’t have a hard contract for prompts. We didn’t have a required “read these files first” step. We didn’t have a rule about whether assistants could refactor adjacent code. So each assistant made a locally reasonable choice, and the combined result was unstable.
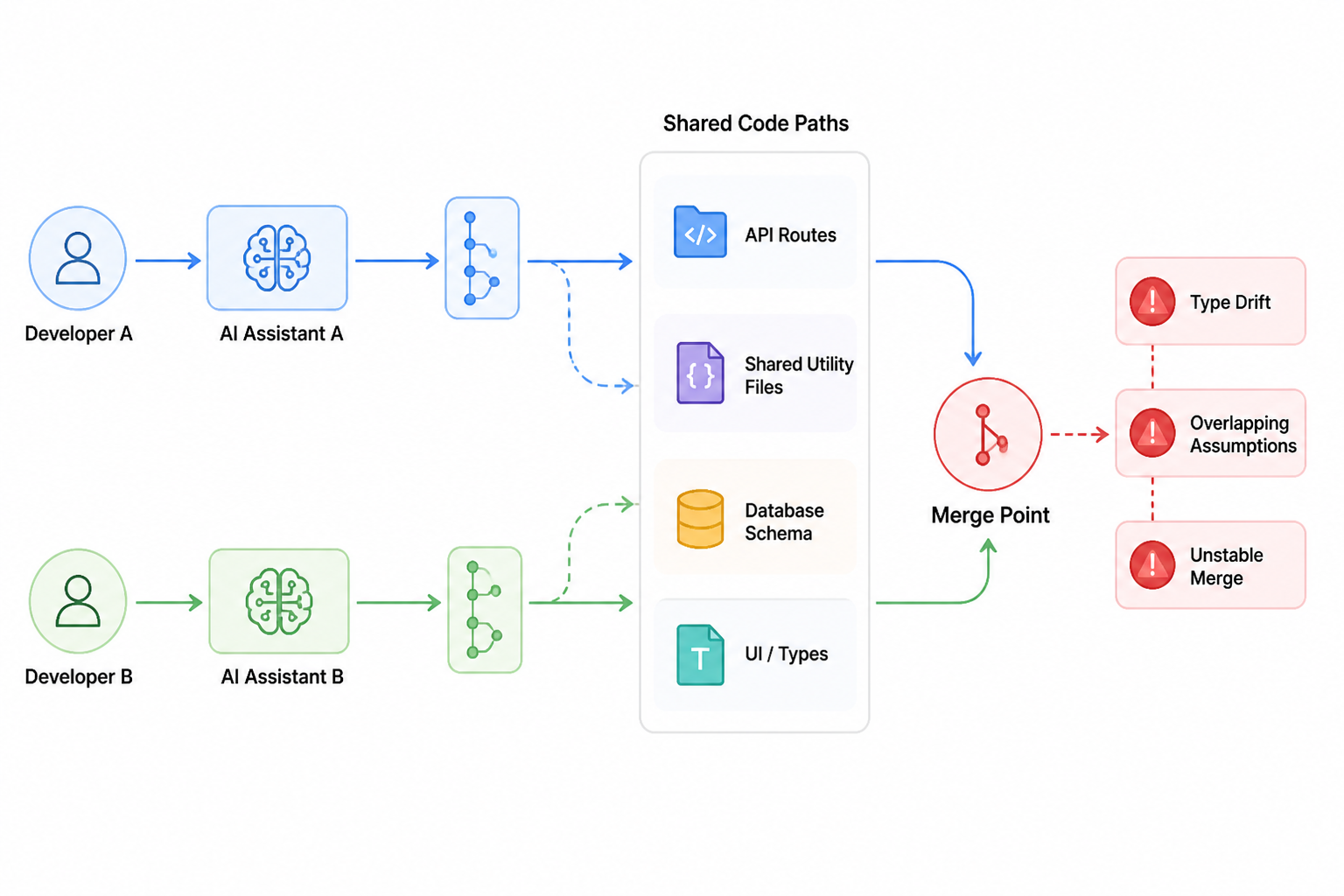
What broke first: shared types drifted faster than the UI
The first repeat failure was type drift. We’d change a backend response shape on one branch, then the other branch would add UI against the old shape because the assistant had cached context from earlier files or because the prompt included an older example.
A typical version looked like this. Developer one changed a job status object from:
{ status: “running”, progress: 40 }
to something more explicit:
{ state: “running”, percentComplete: 40, startedAt: … }
That was a reasonable change. It made the API clearer. But on another branch, the UI assistant was told to “show a progress bar for running jobs using the existing job status payload.” It scanned examples, found status and progress in nearby files, and built a clean component around fields that no longer existed on main.
No one caught it immediately because each branch worked against its own snapshot. The merge didn’t create a syntax conflict. It created a semantic one. The frontend compiled. The progress bar stayed empty.
Who fixed it? Usually the person merging later, which was often me. That’s one of the annoying patterns here. The cost didn’t fall on the person who created the mismatch. It fell on whoever had enough context to see both sides.
We changed two things after this kept happening. First, we moved shared API shapes into one place and made the frontend consume those types instead of re-declaring them. Second, our prompts started naming the source-of-truth file explicitly. Not “use the existing job status payload.” Instead: “Read types/job.ts and api/jobs/[id].ts. Use the exported JobStatusResponse type exactly. Don’t infer fields from usage examples.”
That one prompt change cut out a lot of nonsense.
The second breakage: both assistants touched the same helper differently
The nastier failures came from shared helper functions. These weren’t obvious conflict points because they looked small. A formatting utility. A request wrapper. A query builder. AI assistants love these files because they look central and easy to improve.
We had one helper that normalized user input before saving records. One assistant changed it to be stricter because a backend task needed cleaner inputs. The other assistant, working on a UI flow, changed it to preserve more original text for display consistency. Both edits were “correct” inside their task framing. Together they broke a form flow in a way that looked random.
The bug report from our own testing was basically: “Why does this field save differently depending on whether it was created from the modal or inline editor?” The answer was ugly. Two call paths now relied on subtly different expectations from the same helper.
This class of problem took longer to diagnose because the code still looked tidy. There was no obvious AI smell. No weird comments. No hallucinated library. It was a coordination failure wrapped in decent code.
What fixed it wasn’t a smarter assistant. It was narrowing edit scope. We added a rule that prompts had to say whether helper changes were allowed. If the task was UI-only, the prompt said “do not change shared utilities unless you stop and explain why first.” If the task required touching a shared helper, we treated that as its own branch and review point.
That felt slower for about two days. Then it made us faster because we stopped stepping on the same rakes.
File discovery was worse than code generation
I expected the hard part to be getting good code out of the assistants. It wasn’t. The hard part was getting them to look at the right files before they wrote anything.
If you let an assistant start coding from a broad prompt in a medium-sized repo, it will anchor on whatever file fragments it sees first. Sometimes that’s fine. Sometimes it means it updates a dead component, copies a pattern we already decided to retire, or recreates logic that had been moved to a service layer last week.
We saw this a lot with forms. The repo had evolved from direct form handlers to a more centralized action pattern. One assistant had enough recent context to use the new pattern. The other would still find old examples and generate code that looked plausible but reintroduced the older style. Same app. Same feature area. Different historical slice of the codebase.
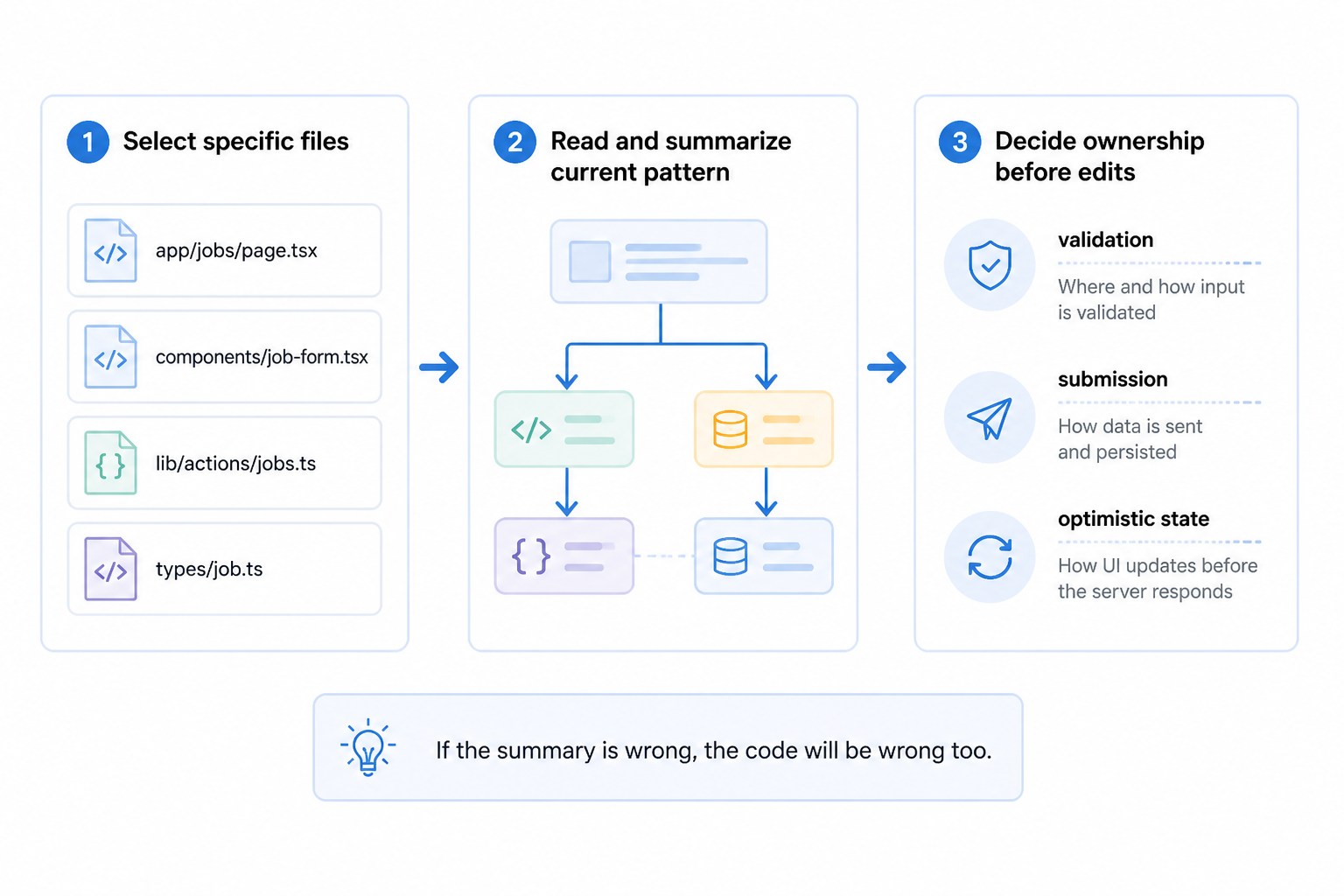
So we changed the shape of the work. Before asking for edits, we started with a read step. Not a generic “analyze this codebase.” A targeted one. For example:
Read these files only and summarize the current pattern before changing anything:
app/jobs/page.tsx,components/job-form.tsx,lib/actions/jobs.ts,types/job.ts. Tell me which file should own validation, submission, and optimistic state.
That did two useful things. It made the assistant commit to a map of the current architecture, and it gave me a fast way to see whether it had understood the system before I let it write code. If the summary was wrong, the code would be wrong too.
Refactors were the biggest source of hidden damage
The assistants were often most impressive when asked to refactor. They could rename things consistently, extract duplicated blocks, and reorganize components faster than either of us would by hand. But in a shared branch flow, this was also where the most hidden damage came from.
One of us would ask for a cleanup pass while the other was building a feature on top of the old names and file structure. The cleanup branch would land first because it looked low risk. Then the feature branch would explode into a mess of false conflicts and stale references.
A human doing a refactor usually has some instinct for “this will annoy anyone else touching this area today.” The assistants don’t. If you ask them to improve structure, they will. They don’t care that someone else is halfway through wiring that exact component.
We ended up with a simple rule: no AI-generated refactors on active feature surfaces unless the refactor itself was the task and we agreed on it first. Cosmetic cleanup became end-of-cycle work, not background work. Boring rule. Very effective.
Database changes exposed the weakest coordination
Schema work was where bad assumptions got expensive. If one assistant changed a model name, relation, enum value, or nullable field and another assistant generated code from the old schema, we got a chain of failures: migration confusion, stale type generation, wrong form defaults, and runtime issues that didn’t show up until a specific path hit the database.
One real pattern was enum drift. We changed a status field to support a clearer lifecycle. One branch updated the schema and backend transitions. Another branch added UI filtering using the old enum values because the assistant had seen existing labels in the frontend and echoed them back as if they were still valid. The result wasn’t one bug. It was three:
- filters that returned no rows
- bad badge rendering for new records
- a background job branch that never matched the new terminal state
We fixed this by slowing schema changes down and tightening the order of operations. Schema branch first. Migration and generated types second. UI and job logic after that. Also, every prompt that touched status logic had to include the current enum definitions in plain text or point to the generated type file directly.
That sounds obvious. We weren’t doing it at first because it felt redundant. It wasn’t redundant. It was the only way to stop the assistants from reconstructing a world that no longer existed.
Tests didn’t save us as often as I expected
I like tests. They helped. But they didn’t catch the main class of failures early enough because many of the problems were contract mismatches across branches, not isolated logic bugs inside one branch.
If branch A changes a response shape and updates the tests, and branch B builds UI against the old shape with no test covering that integrated path, both branches can look green alone. The failure appears after merge. That’s not a test problem exactly. It’s an integration timing problem.
What helped more than increasing unit test count was adding a few thin end-to-end checks on critical workflows and running them after rebasing. We also got stricter about regenerating anything codegen-related before merge. The assistants were bad at remembering generated artifacts unless explicitly told.
One recurring fix was adding a pre-merge checklist in plain language:
- rebase on latest main
- regenerate schema-derived types if relevant
- run critical flow tests
- scan changed files for accidental refactors outside scope
- read API and UI contracts side by side if payloads changed
None of that is fancy. It worked because the failure modes were repetitive.

Who fixed what depended on who held the wider context
I wanted a cleaner answer here. Something like “everyone fixed their own AI’s mistakes.” That isn’t what happened.
The person with the broader architectural picture usually fixed the integration bugs, even if they didn’t create them. That was often the same person across several days, which creates a hidden tax. AI can speed up feature output while concentrating cleanup work on whoever understands the system boundaries best.
That’s a real management problem for a tiny team. Velocity looks great if you count code produced. It looks worse if one person becomes the reconciliation layer between multiple assistants and multiple branches.
We had to make that visible. During review, we started labeling issues by category instead of treating everything as generic cleanup:
- prompt scope failure
- stale context failure
- shared contract drift
- unapproved refactor
- missing repo read before edit
That sounds bureaucratic, but it helped because the fix wasn’t always “write better code.” Sometimes the fix was “stop asking the assistant to infer architecture from fragments.”
What changed in our prompts
The biggest improvement came from making prompts narrower and more explicit about constraints. Early prompts were task-first. Later prompts were repo-first.
An early version looked like this:
Add job progress UI to the dashboard and wire it to the existing API. Keep the style consistent.
A later version looked more like this:
Read
app/dashboard/page.tsx,components/job-row.tsx,types/job.ts, andapi/jobs/[id].ts. Summarize the current data flow in 5 sentences max. Then update onlycomponents/job-row.tsxand, if required,types/job.ts. Do not rename props, move files, or refactor unrelated code. Use the exported response type. If the API payload is missing needed data, stop and report that before changing UI code.
That’s less pleasant to write. It saves time because it reduces freelancing. We also started asking the assistant to list planned file edits before generating code. If it proposed touching seven files for a two-file task, that was a warning sign.
What changed in branch strategy
We stopped pretending every task could happen in parallel. Some tasks can. Shared-contract work usually can’t.
We got better results after separating work into two categories. Surface work could run in parallel: isolated UI changes, copy, styling, contained components. Contract work needed sequencing: schema updates, API shape changes, shared utility changes, auth flow changes, queue behavior, anything that crossed layers.
If a task crossed layers, one person handled the contract branch first. Once that landed, the second person could use AI to build on top of stable ground instead of moving ground.
This cut back on the fake speed of parallelism. It also reduced the number of fixes that had to be done by the person with the broadest mental model.
The surprising part: AI disagreement was useful when we surfaced it early
There was one upside to having two developers with two assistants. When both assistants approached the same problem differently, that sometimes exposed ambiguity in our architecture. If one wanted to put validation in the form and the other pushed it into a shared action, the real question wasn’t which assistant was smarter. It was whether we had made the ownership boundary clear in the codebase.
Once we stopped treating disagreement as noise, it became a signal. But only when we caught it before merge. After merge, it’s rework.
What I’d do from day one next time
If I were starting Hot Glue again with multiple people and multiple AI assistants on one repo, I’d put these rules in place immediately: