The audit took one session. Fixing what it exposed took much longer.
I sat down to do what I thought would be a quick documentation pass on Hot Glue. The codebase was still working. The latest features were shipped. The AI-assisted workflow felt productive. But the written context around the code had started to rot. Not the code itself. The explanations, setup notes, architecture docs, prompt snippets, environment assumptions, and “temporary” comments that were supposed to help me and future collaborators understand what was going on.
After ten layers of feature work, the repository had drifted into a familiar state: the app was more real than the docs. That’s normal in fast product work, but AI speeds up the mismatch. I could ask for a migration, a refactor, a webhook handler, a retry queue, or a cron fix and get useful output fast. What didn’t update at the same pace was the human-readable map of the system. So a single audit session ended up finding context failures in almost every direction.
The key insight was simple. AI didn’t only help me build faster. It also made stale context compound faster, because every new prompt inherited assumptions from old files, old comments, and half-true docs. Once that starts, the assistant keeps producing locally plausible changes inside a globally inaccurate story of the app.
That was the real bug.
What I audited
I wasn’t trying to produce polished docs. I wanted a reliable operating picture of the project as it actually existed that day. So I checked the places where context tends to spread and diverge:
- README and setup instructions
- architecture notes and feature docs
- environment variable references
- inline code comments around core flows
- saved prompts and AI handoff notes inside MakerWS
The app had grown in layers. A basic product shell turned into authenticated flows, database changes, background jobs, file handling, queue retries, more structured prompts, and a lot of edge-case handling. None of that happened in a neat top-down design process. It happened through repeated implementation loops: make a change, test it, patch what broke, then add one more feature on top.
That style of building works. I still prefer it for early products. But it leaves a paper trail full of ghosts.
The first thing I found: setup instructions described a version of the app that no longer existed
The README was the easiest place to start, so I expected a few small edits. Instead, it described an older startup path, older environment requirements, and a previous assumption about how local services were wired together. The app had moved on. The README hadn’t.
A few examples:
- It told me to create environment variables that had been renamed.
- It skipped variables that were now required for background processing.
- It implied one service was optional even though later features depended on it.
- It described an init flow that had been replaced by a seeded bootstrap script.
Each one looked minor on its own. Together they explained why a new session with AI would sometimes veer off course early. If the README said one thing and the code said another, the model often treated both as valid and merged them into a third answer that was wrong in a fresh way.
That pattern showed up again and again during the audit. Stale context didn’t block progress cleanly. It bent it.
Architecture docs had become historical documents
I had an architecture note that started out useful. It explained how requests came in, where state lived, what happened asynchronously, and which parts were intentionally thin because I was still validating the product. At the time, it was accurate.
After enough changes, it turned into a history file masquerading as a current map. The audit surfaced three kinds of drift inside it.
- Components still existed, but their responsibility had changed.
- Components had moved, but the doc still implied the old file boundaries mattered.
- The critical path now included queueing and retries, but the doc still described synchronous behavior.
This kind of drift is dangerous because it feels authoritative. A rough note in a scratchpad is obviously temporary. A document called architecture looks final even when it’s not. AI tools also give that file more weight than it deserves, because it reads like summary context. So the worse it gets, the more confidently it poisons future generations of code and explanation.
I didn’t delete the file. I split it. One part became “current system shape” and another became “historical decisions.” That removed the worst ambiguity. If I wanted to know why I once did something, I could still find it. If I wanted to know how the app worked now, I had a shorter document with present-tense claims I could verify against the code.
Environment variable docs were where the hidden complexity accumulated
Environment setup drifted faster than anything else. That’s not surprising. Variables get added under deadline pressure, renamed during cleanup, duplicated during migrations, then half-removed when a service changes. AI makes this easier to create because it’s very good at inserting configuration changes in the moment and very bad at maintaining a clean lifecycle around them unless you force it to.
In Hot Glue, I found variables in four states:
- required and documented
- required and undocumented
- documented but no longer used
- still referenced in one code path but no longer conceptually part of the app
The fourth category caused the most confusion. These were values that survived in a fallback branch, old deployment script, or low-traffic admin path. They weren’t central anymore, but they still existed enough to make a model think they mattered. So prompts like “help me simplify deployment” would often preserve dead configuration because the code still mentioned it somewhere.
I fixed this with an approach that was boring and effective. I made one canonical environment reference table, then I checked every variable against actual usage. If a variable was not active, I removed it from the main reference and moved any explanation into a short migration note. That stopped dead config from looking alive.
| State found in audit | Action taken |
|---|---|
| Required and documented | Kept and verified against runtime usage |
| Required and undocumented | Added to canonical reference with purpose and owner flow |
| Documented but unused | Removed from active docs |
| Referenced only in legacy path | Moved to migration note or deleted after code cleanup |
That table wasn’t fancy. It was enough.
Inline comments were often the most misleading text in the repo
I expected top-level docs to drift. I underestimated how much damage old inline comments could do. Some were left from earlier implementations. Some described intent that had changed. Some were written while debugging and never removed after the final fix landed. In several files, the code was correct and the comment above it was the lie.
That’s worse than having no comment. A wrong comment frames how I read the next fifty lines. It also frames how the AI reads them. If the comment says “synchronous fallback” but the code now enqueues work, the model starts reasoning from a false premise before it even parses the function body.
So during the audit I used a simple rule. Comments had to earn their place. If a comment only restated the code, I cut it. If it explained a non-obvious trade-off, constraint, or failure mode, I kept or rewrote it. If it described behavior, I verified it line by line.
If a comment couldn’t survive a direct comparison with the code under it, it had to go.
That made the files look a little barer, but the remaining comments became useful again. Sparse and true beat dense and stale.

Prompt history inside MakerWS had turned into accidental architecture
This was the part I didn’t expect to matter so much. I had prompt fragments, implementation notes, issue-specific debugging prompts, and handoff summaries inside MakerWS. They weren’t formal docs. They were working memory. But after enough sessions, they started acting like shadow documentation.
Some of those notes were still excellent because they captured why a workaround existed or why I chose one path over another. Others had expired quietly. They referred to file names that changed, old assumptions about schemas, or one-time cleanup steps that looked permanent if you read them out of context.
The problem wasn’t only that they were old. The problem was that I was still pasting pieces of them into new prompts. That meant stale context was being promoted back into the active development loop.
I changed how I stored these notes. Instead of keeping one growing thread of prompt residue, I split them into three buckets:
- current implementation context
- historical decisions
- debugging artifacts to expire or delete
That reduced accidental reuse. It also made me state whether a note was a live instruction or an old trail marker. AI-assisted work needs that distinction more than manual coding does, because context injection is part of the build process itself.
The code was less confused than the surrounding explanations
One thing became obvious during the session. The repository wasn’t collapsing under technical debt in the dramatic sense people usually mean. The app still ran. Tests that existed still passed. The newest features mostly reflected current reality. The real instability lived in the mismatch between implementation and explanation.
That’s a different kind of debt. It doesn’t always break production. It breaks iteration quality. It makes future changes slower, because every task starts with a hidden validation phase where I have to figure out which text is still trustworthy. With AI in the loop, that trust problem gets amplified. The model doesn’t know which source rotted first. It treats old confidence and new confidence as peers unless I structure the context well.
So the audit changed my mental model. I stopped thinking of docs as a passive output of development. In this workflow, docs are active inputs to future generations of code. If they drift, they don’t merely fail to inform. They distort.
What I changed after the audit
I didn’t try to solve this with a giant documentation rewrite. That would’ve created another polished layer that would age badly. I made a smaller set of structural changes that fit how I actually build.
- I created one “start here” file that points to current truth sources.
- I separated current-state docs from historical decision logs.
- I shortened setup instructions so they only cover the live path.
- I removed comments that were explanation-shaped clutter.
- I added a lightweight audit checklist to run after major feature layers.
The last one mattered most. The issue wasn’t that I failed to document once. The issue was that ten rounds of feature work happened without a context audit. So I stopped treating documentation review as cleanup for later and started treating it as a maintenance task tied to shipping meaningful changes.
That checklist is simple. After a feature layer lands, I ask:
- Would a new session know the right setup path?
- Did any environment assumptions change?
- Did any comments become false?
- Is there a document that now describes history instead of current behavior?
- Would I paste any of this context into a future prompt without editing it?
If the answer to the last question is no, that text needs work or deletion.
What surprised me most
I expected the audit to reveal neglect. Instead, it revealed accumulation. Most of the drift came from documents that were accurate when written. They weren’t careless. They were stranded. The product changed underneath them and nothing forced a re-sync.
That matters because the fix isn’t “document better” in the abstract. The fix is to tighten the feedback loop between code changes and context changes. In AI-assisted development, context should be treated more like configuration than like prose. It needs current ownership, clear status, and routine pruning.
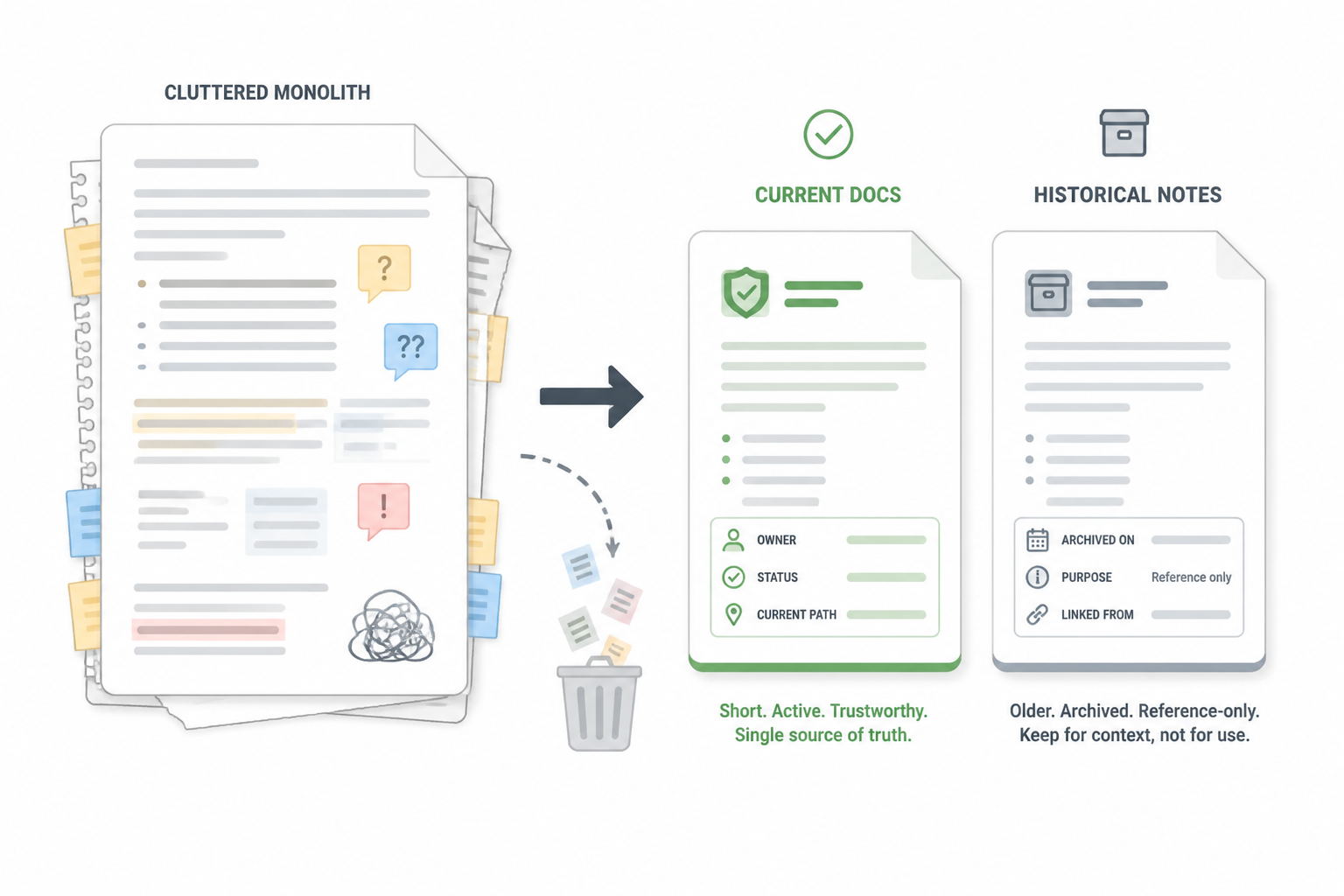
I was also surprised by how often the right move was deletion. I kept wanting to update old files, but many of them had passed the point where patching helped. A shorter current doc plus a small historical note was cleaner than one giant file full of caveats, exceptions, and old paths. Less text gave better results because the remaining text had a clearer contract with reality.
The trade-off I accept now
I don’t expect every document in Hot Glue to stay perfectly synchronized. That’s not realistic, and forcing it would slow down the kind of fast iterative building that made the project possible. But I do expect every document to declare what it is.
Current setup guide. Historical architecture note. Active implementation context. Expiring debug scratchpad. Those labels sound small, but they change how both humans and AI interpret the text. A stale historical note is fine if it’s clearly historical. A stale “current system overview” is a trap.
So the standard I use now isn’t completeness. It’s trustworthiness. I want less documentation, but I want the remaining pieces to be safe to use as prompt input and safe to hand to someone else without a live translation layer from me.
Why this audit mattered more than another feature sprint
Shipping another feature would’ve moved the product forward. This audit improved the ground the next ten features will stand on. That’s why it mattered. Once context starts rotting around the code, every future task gets slightly noisier. The AI proposes more wrong branches. Setup gets harder to trust. Old comments keep reintroducing retired ideas. Small confusion compounds.
The code had changed ten times. The story of the code hadn’t kept up. One session made that visible. After that, I couldn’t ignore it.
If you’re building this way inside MakerWS, that’s the part I’d watch. Don’t only track whether the app works. Track whether the context you’re feeding back into the loop still matches the app you actually have. Once those diverge, you’re not coding on a clean base anymore. You’re coding inside a pile of half-true memories.
And those memories will write code with you unless you clean them out.