The session was producing code, but it had stopped producing clarity
We killed the AI session while it was still writing valid code.
That was the right call.
The failure mode wasn’t obvious at first because nothing had fully exploded. The app still ran. New functions appeared quickly. Files kept getting updated. The model sounded confident. But six layers in, the system had become hard to reason about. A small feature request was bouncing across too many files, too many abstractions, and too many assumptions that had been invented mid-conversation. We weren’t building anymore. We were negotiating with the residue of the previous prompts.
This post is about that moment. Not the dramatic version where the AI destroys the repo, but the more common one where the session becomes subtly expensive. You ask for one change and get three side effects. You ask why a thing works and the explanation references code paths nobody would’ve designed on purpose. The AI isn’t useless at that point. It’s context-saturated. Those are different problems, and the fix is different too.
In MakerWS, I hit that wall building Hot Glue. The feature itself wasn’t huge. The complexity came from the way the session had grown around earlier choices, partial fixes, and “good enough for now” scaffolding. So I stopped, wrote down what was actually true, opened a fresh session, and rebuilt the mental model before touching more code.
That reset saved time, reduced code, and made the next round of AI output far better.
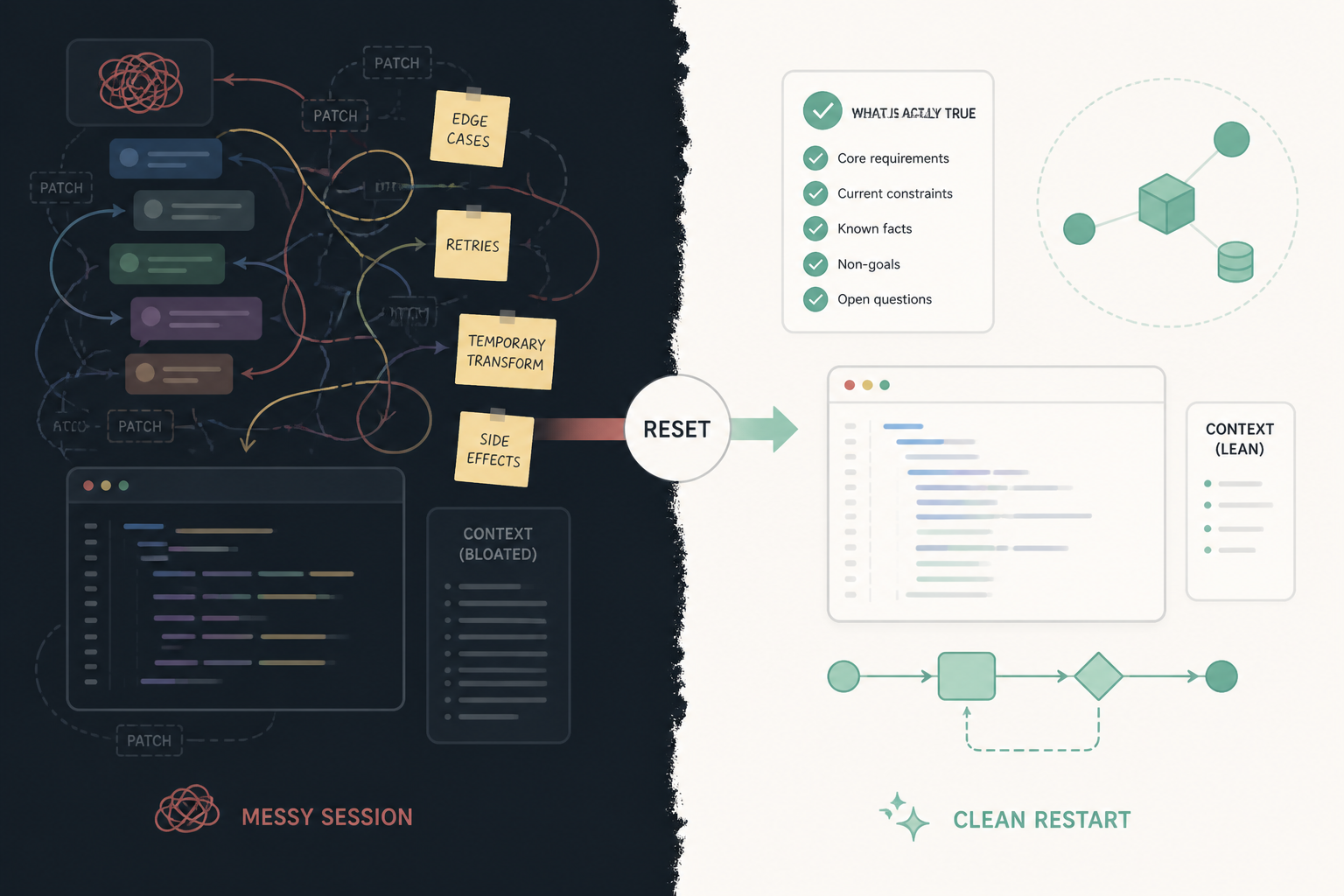
What the bad session looked like in practice
The session didn’t go bad in one step. It drifted.
I started with a normal build loop. I had a feature target, the codebase loaded in MakerWS, and a working conversation with the model. Early on, it was useful. I asked for a schema change, then an API route, then a UI update. The model could see enough local context to make coherent edits. It moved fast because the problem was still narrow.
Then I added edge cases.
We needed one fallback path for records with incomplete metadata. Then another path for retries. Then a temporary transform because imported data wasn’t shaped consistently. Then a status mapper because one part of the app expected internal labels and another expected display labels. None of those decisions was crazy on its own. The problem was accumulation. The model kept solving the latest issue by wrapping the previous solution instead of simplifying the whole path.
That gave me a stack that looked productive from the outside. Inside, it had turned into translation on top of translation. A request came in, got normalized, then mapped, then augmented, then passed through a helper that had originally been written for a slightly different use case. A React component was receiving data in a shape that existed only because another function had been patched to keep old rendering code alive. The session remembered why each patch existed. I didn’t trust that memory anymore.
The warning signs were concrete:
- The same concept had two or three names in different files.
- Fixes started requiring companion fixes in places that shouldn’t have been related.
- The AI explained behavior historically instead of structurally.
- I was reading diffs and thinking, “yes, I guess that works,” instead of “yes, that’s the right model.”
- A simple change request started with too much setup because the session needed reminders about old caveats.
That’s the point where velocity becomes fake. Tokens are flowing. Commits are happening. But the build loop is getting worse.
The exact moment I stopped trusting the thread
The break came when I asked for a small UI behavior change and got back a fix that touched state management, validation, and a server transform.
Technically, the AI had a reason. In the current shape of the code, those pieces were connected. That’s what made it a problem. They shouldn’t have been.
I asked a follow-up: why does the UI need the server transform at all? The answer was coherent, but it depended on two prior workarounds and one inferred requirement that had never actually been stated. The model had built a plausible world and was now coding inside it. Some of that world matched the product. Some didn’t. I couldn’t tell which parts were earned and which parts were sediment from earlier prompts.
Once that happens, continuing the same session is usually a mistake. The model is no longer reading the codebase cleanly. It’s reading the codebase plus the narrative it has built about the codebase. That narrative can help for a while. Then it starts steering implementation.
The trigger wasn’t “the code is broken.” It was “the explanation now costs more than the feature.”
What I did before opening a new session
I didn’t kill the thread and immediately re-prompt. That loses the one useful thing the bad session still had, which was a record of decisions, even messy ones.
First I pulled out the facts.
I opened the files that had been touched most recently and wrote a scratch summary outside the chat. Not polished notes. Plain statements. What data comes in. What shape it should have. Where it changes. Which files are temporary glue. Which functions feel suspicious. What the feature is actually supposed to do now, not what it was supposed to do three prompts ago.
I also split assumptions into two groups:
- Requirements I knew were real because they came from the product behavior I wanted
- Implementation assumptions that existed only because the current session had introduced them
That distinction matters a lot. AI sessions blur it fast. A workaround appears, survives for a few turns, and starts feeling like architecture. It isn’t. It’s residue unless you’ve chosen it on purpose.
Then I checked the code itself. I looked for the narrowest possible path through the feature. If I removed the helper chain, what was the clean data contract? If I ignored temporary compatibility, what shape should the component really consume? If the route were rewritten from scratch, what would it return?
By the end of that pass, I had something the old session no longer had: a stable description of the system that wasn’t tangled up with the conversation history.
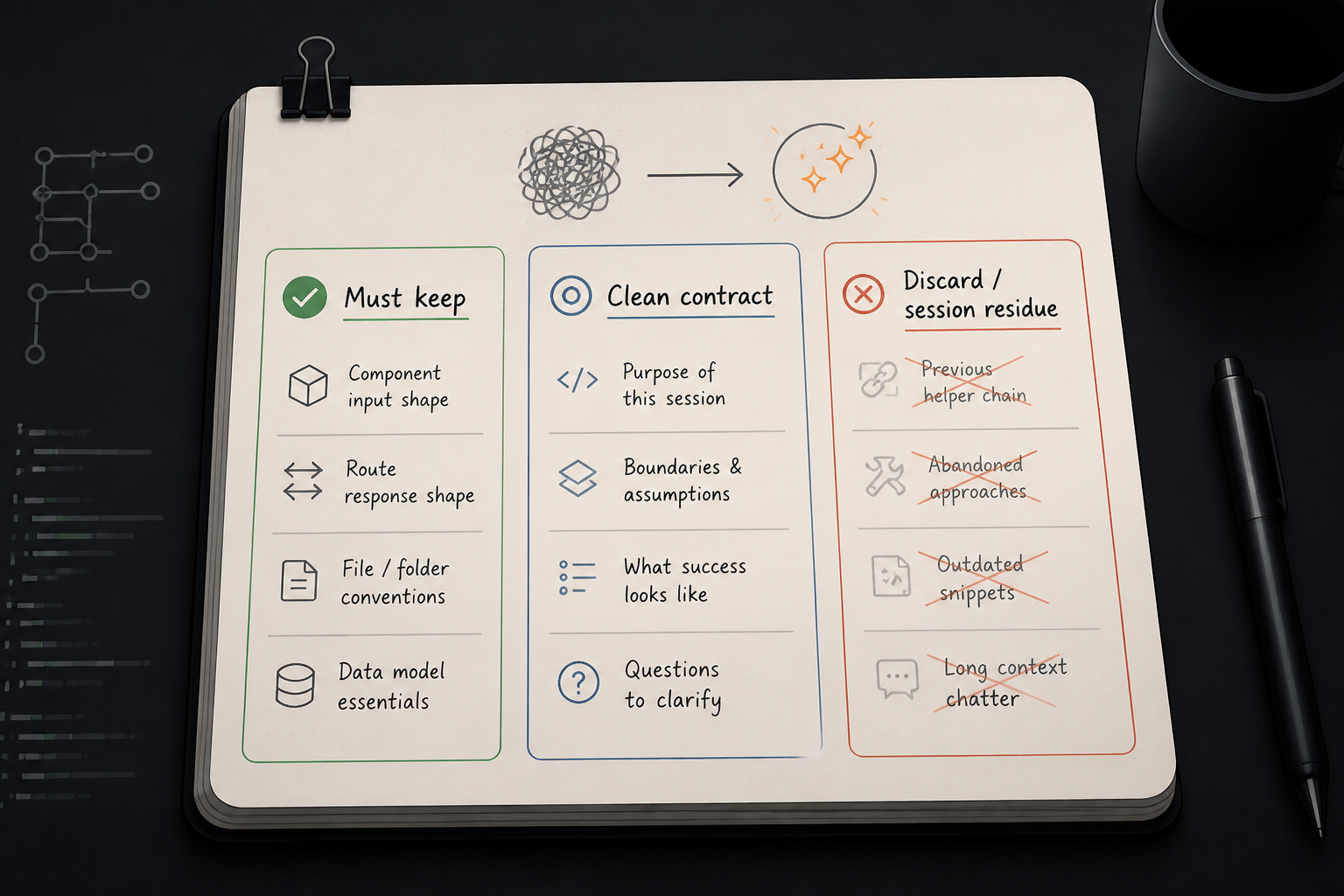
The reset prompt I used
The new session started with constraints, not a feature request.
I gave it a compact map of the current system, the desired end state, and the parts I no longer trusted. I named files. I named the data shapes. I told it which paths were likely overengineered. I explicitly said not to preserve prior abstractions unless they were necessary.
The core of the prompt was basically this in plain language: here’s what the feature must do, here’s the current file layout, here’s the clean contract I want, identify the minimal set of changes to get there, and call out anything that exists only for backward compatibility or because a previous session overfit the problem.
I also changed the task order. In the old thread, I had been asking for edits directly. In the new one, I asked for a diagnosis first. That forced the model to rebuild understanding from the repository state instead of continuing the old storyline.
That first answer was noticeably better. Shorter too. It pointed at the same files I already suspected, but it removed one whole transformation layer I had mentally accepted as unavoidable. It also identified a state shape mismatch that explained why the UI had become so dependent on defensive code.
Fresh context didn’t magically make the model smarter. It made the problem legible again.
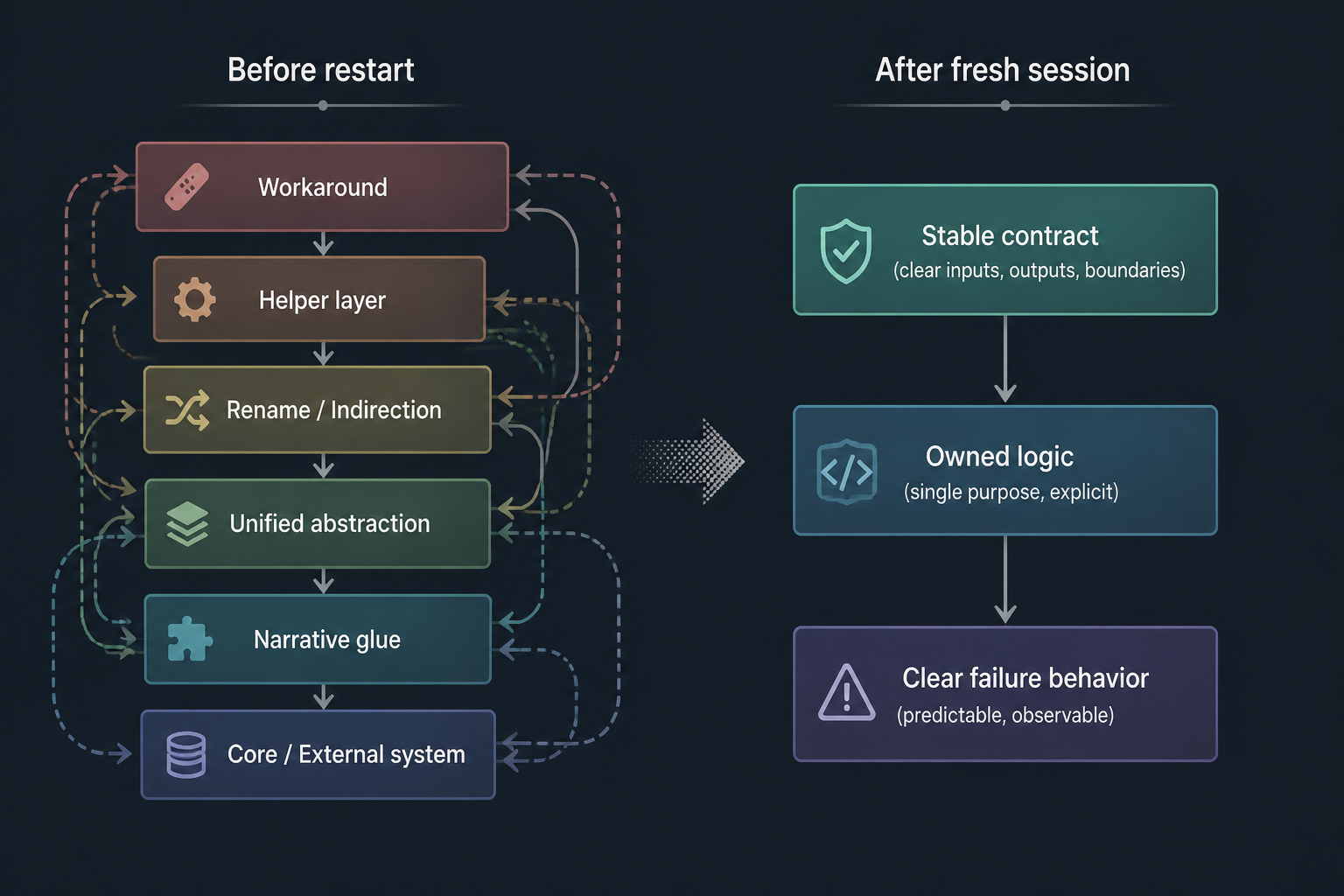
What changed after the restart
The code got simpler fast, but the important part was where it got simpler.
We stopped translating the same object multiple times. One shared type became the source of truth for the data coming out of the route and into the component. A helper that had been carrying old conditional logic disappeared. A validation branch moved closer to the input boundary where it belonged. The UI component lost props that only existed because earlier code had split one concept into several flags.
I also changed how I used the AI after the restart. Instead of asking “implement this,” I more often asked “show me the narrowest path” or “which layer owns this responsibility?” Those prompts produced fewer decorative edits. The model was less likely to preserve accidental complexity when the target was ownership and scope instead of completion.
One useful side effect was that testing became obvious again. In the messy version, it wasn’t clear where to assert behavior because logic was distributed across normalization, transformation, and rendering safeguards. In the cleaner version, I could test the route contract and the component expectation separately. That told me we had actually improved the system, not only rephrased it.
The trade-off: restarting costs time, but continuing can cost the whole shape of the feature
There is a real cost to starting over. You lose local momentum. You have to restate context. Sometimes you’ll discover the old session had encoded a subtle edge case you forgot to mention. A restart can feel like giving up progress.
But continuing a degraded session has a worse failure mode. It preserves the wrong shape because the model is trying to stay consistent with its own prior choices. You end up paying for compatibility with mistakes that were never meant to survive.
I think of it like this: if the session still helps me see the architecture more clearly, I keep going. If the session starts asking me to remember why the architecture became weird, I restart.
That sounds subjective, but there are some concrete signals.
Signals that it’s time to fire the AI session
- A small request now requires edits across unrelated layers.
- The same entity has multiple competing shapes or names.
- The model keeps preserving compatibility for code you no longer want.
- You can’t explain a data flow in one pass without referencing historical fixes.
- The diffs are plausible but don’t reduce confusion.
For me, the strongest signal is this one: when I start prompting around the session instead of through the code. If I’m spending a lot of words correcting the model’s accumulated assumptions, the context window is already polluted. A fresh session is usually cheaper than another hour of careful steering.
What I keep from the old thread, and what I throw away
I don’t treat a bad session as wasted work. I treat it as a noisy draft.
Here’s what I keep:
- Any code that clearly reduced duplication or clarified contracts
- Error cases that surfaced real product requirements
- File-level knowledge about where the feature actually touches the system
- Examples of bad abstractions, because they help define the next prompt
And here’s what I throw away without guilt:
- Narrative explanations that only make sense if every prior workaround remains in place
- Helper layers created to preserve temporary structure
- Renames or indirections that made the session sound tidy without making the code simpler
- Any “unified” abstraction that arrived before the underlying contract was stable
This is one of the stranger parts of AI-assisted building. The model often gives you something coherent before it gives you something correct. If you’re moving quickly, coherence is seductive. It feels like progress because the pieces line up linguistically. But code quality lives in ownership, contracts, and failure behavior, not in how smoothly the assistant narrates the design.
The part I got wrong the first time
I waited too long.
I saw the warning signs early, but I kept trying to salvage the thread because the model still knew a lot about the feature. That knowledge was real, but it was bundled with too many contingent assumptions. I treated continuity as an asset when it had become a liability.
I also asked the old session to refactor code it had effectively talked itself into. That rarely goes well. The model tends to preserve the premise of the prior implementation unless you explicitly revoke it. If the premise is the problem, a “refactor this” prompt often turns into a cleanup pass over the wrong structure.
The better move would’ve been to stop as soon as the data contract became hard to state plainly. Once the contract blurs, every additional patch multiplies confusion.
What I’d do earlier next time
I’d create reset points on purpose.
Now when I’m deep in a build inside MakerWS, I write compact architecture snapshots as I go. Not every hour, and not in formal docs. Only at the moments where the shape changes. A route becomes the source of truth. A UI state model gets simplified. A temporary adapter is introduced. Those are the points where future sessions either stay clean or inherit confusion.
That gives me a better restart path because I don’t have to reconstruct the system from a contaminated thread. I can start from current reality. It also makes me more willing to end a session early, because restarting no longer feels like erasing context.
I also try to separate prompts into phases:
- understand the current system
- propose the narrowest clean design
- make the edits
- verify edge cases
When those phases collapse into one long ongoing conversation, drift shows up faster. The model starts mixing diagnosis, implementation, and preservation of old assumptions in ways that are hard to unwind.
Starting fresh isn’t failure. It’s context hygiene.
That’s the real lesson from this build.
Firing the AI mid-build felt drastic the first few times I did it. Now it feels normal. Sessions have a useful lifespan. Some last a while because the problem stays well-bounded. Some go stale quickly because they solved three adjacent issues and silently fused them together. The trick isn’t squeezing more output from a tired thread. It’s noticing when the thread has become part of the problem.
Hot Glue got better after the reset because the restart forced me to restate the truth of the system in plain terms. The AI then had something solid to work from. That order matters. Clean prompting isn’t about sounding smart. It’s about stripping away inherited nonsense before asking for more code.
If you’re deep in an AI coding session and the work feels strangely sticky, don’t ask whether the model can still write code. Ask whether the current session still reflects reality. If the answer is no, end it, write down the system you actually have, and start again from there.
The restart wasn’t a retreat. It was the point where the build became understandable again.